

Automatické stahování kurzů ze stránek ČNB
 Karta Data
Karta Data Kde načíst data
Kde načíst data Zadání adresu z webu
Zadání adresu z webu Náhled na data
Náhled na data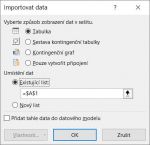 Kam se data načtou
Kam se data načtou Data načtená v Excelu
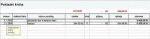
Data načtená v Excelu Využití s funkcí Svyhledat
Využití s funkcí Svyhledat Jak na změnu
Jak na změnu Kde nastavit dotaz
Kde nastavit dotaz Změna adresy
Změna adresy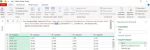 Změna editací dotazu
Změna editací dotazu




Při zpracovávání různých dat ve firmách je někdy třeba přepočítávat hodnoty také na základě aktuálních kurzů vyhlášených ČNB. Je sice snadné jít na stránky banky a potřebné hodnoty opsat, ale možná by někdy bylo jednodušší si umět vždy aktuální hodnoty stáhnout do souboru v programu Excel. Banka totiž umožňuje přístup k daným hodnotám, aby uživatelé nemuseli data opisovat. Tento soubor, který je pro přístup připravený je na adrese:
https://www.cnb.cz/cs/financni-trhy/devizovy-trh/kurzy-devizoveho-trhu/kurzy-devizoveho-trhu/rok.txt?rok=20xx, kde místo 20xx se jen doplní správný rok, například 2021.
Jak se takový soubor v MS Excel připraví
Určitě víte, že v současné době se už Excel umí napojit na různé datové zdroje (databáze), a z nich čerpat potřebná data k dalšímu zpracování. To znamená, že tato data už nyní mohou být bez nějakého speciálního velkého programování přístupná i běžným uživatelům. Stačí se podívat v MS Excelu na kartu Data, kde se mnohé nástroje pro zpracování dat nachází.
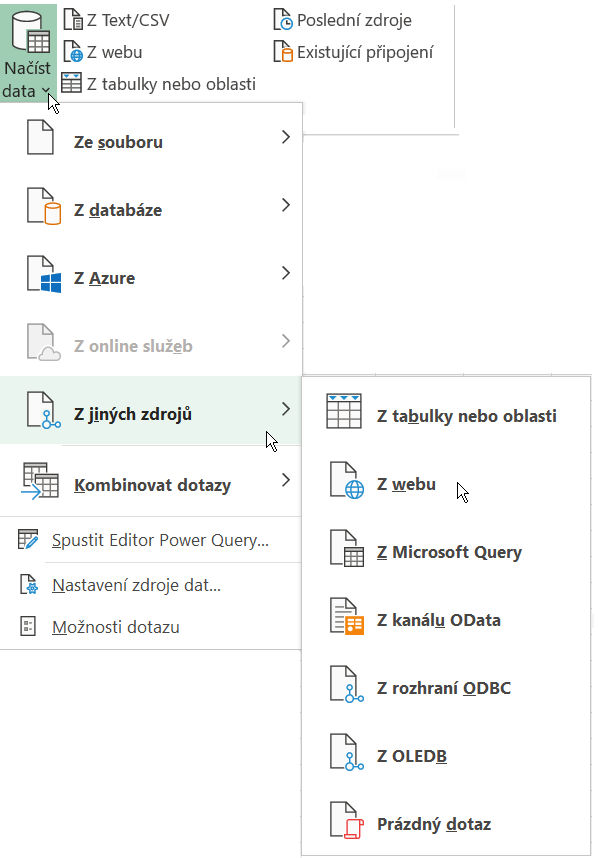
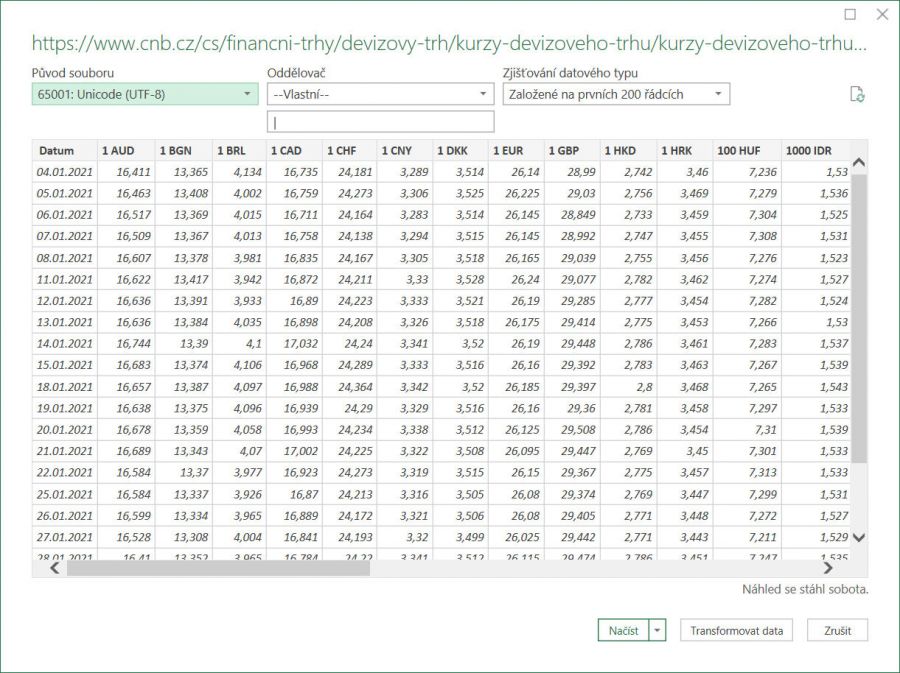
Stačí klepnout jen na ikonu Načíst data a poté ze zobrazené nabídky vybrat položku Z jiných zdrojů. Protože se má načítat z webových stránek ČNB, je třeba dále klepnout na položku Z webu.
Tím se zobrazí dialogové okno pro doplnění URL adresy.
Po zadání adresy, stačí ponechat volbu Základní a klepnout na tlačítko OK. Tím se zobrazí ukázka načítaných dat.
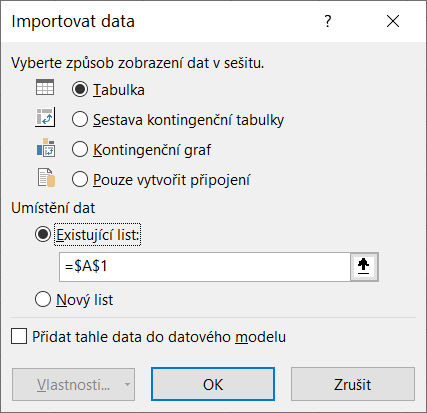
Nyní lze klepnout přímo na tlačítko Načíst nebo pod šipkou tlačítka Načíst se schovává ještě volba Načíst do.
Standardní volba je Tabulka a na Nový list, toto se dá ale změnit podle potřeby.
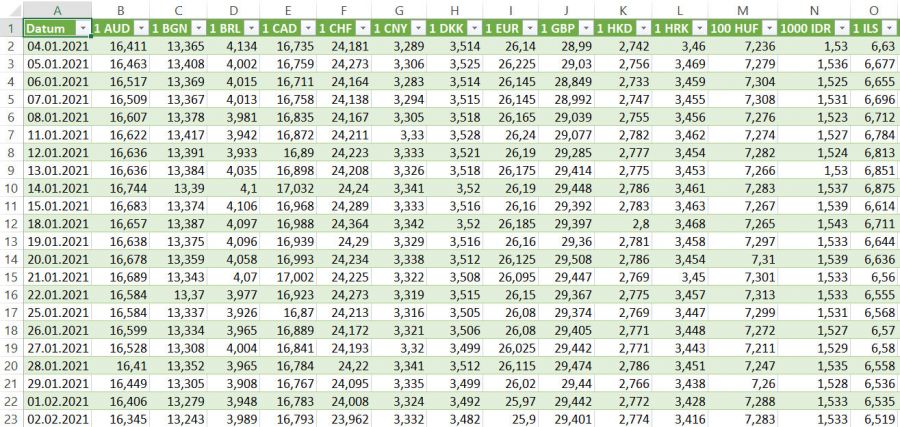
A po klepnutí na tlačítko OK se již načtená data přímo zobrazí v MS Excelu.
Zajímavé je i to, že celá načtená oblast je zároveň i pojmenovaná. Její název je rok. Při odkazech na tuto oblast (například když je třeba pracovat s vyhledávacími funkcemi) není třeba označovat celou oblast, ale stačí opravdu jen se odkázat pomocí názvu rok.
Pro aktuální data pak stačí příště jen klepnout na kartě Data na ikonu Aktualizovat vše (Aktualizovat).
Využití dat s funkcí Svyhledat
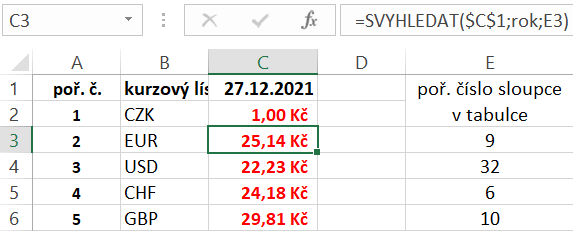
Pokud je třeba vybrat kurzy jen některých měn jen k určitému datu, pak je užitečné využít právě funkci Svyhledat.
Na obrázku (Využití s funkcí Svyhledat) je vidět, že stačí zapsat datum a v buňkách pod ním se vypíšou jednotlivé hodnoty vybraných měn.
Hledá se v prvním sloupci podle zadaného data v tabulce s názvem rok. Funkce pak vrací hodnotu ze zadaného sloupce (třetí argument). Protože je tabulka seřazená vzestupně, může být poslední čtvrtý argument vynechán nebo zadáno pravda.
Jak je to se změnou načítaného souboru
Při nástupu dalšího roku je třeba změnit odkaz na název souboru na serveru ČNB. To znamená je třeba změnit název souboru, z kterého se data načítají. Existuje několik způsobů, jak se k této změně dostat. Například lze klepnout na zobrazené kartě Dotaz na ikonu Upravit.
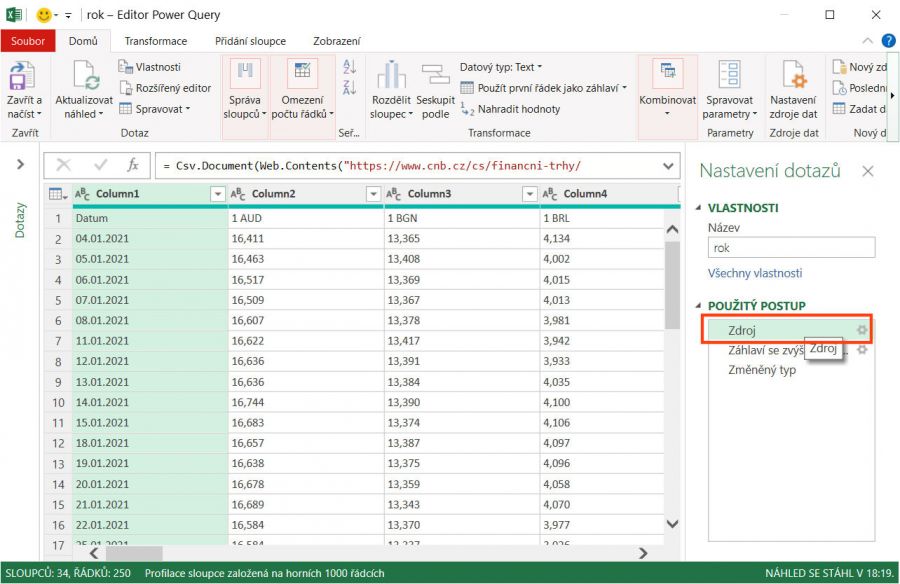
Tím se zobrazí okno editoru Power Query, ve kterém se dá toto změnit či nově nastavit. Je potřeba se nějak dostat do okna pro změnu dotazu. Pro rychlou změnu lze například v levé části okna (podokno Nastavení dotazů) udělat dvojklik na položku Zdroj.
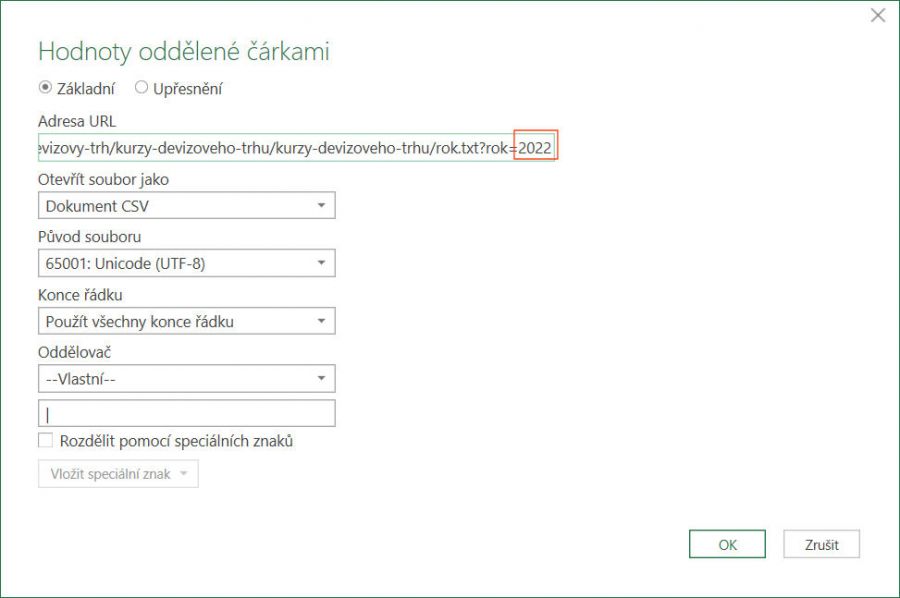
Tím se zobrazí okno, které vypadá stejně jako při úvodním zadávaní připojení. Zde pak stačí jen v políčku Adresa URL opravit.
Po klepnutí na tlačítko OK se připojení opravit.
Pro pokročilejší uživatele nebo uživatele, kteří mají zkušenosti s doplňkem Power Query, je vhodné zkusit i jiné způsoby, například přímo přes editaci dotazu.