

Nově přidané textové funkce v Excelu
 Funkce Textpřed
Funkce Textpřed Použití funkce Textza
Použití funkce Textza Funkce Rozdělit.text
Funkce Rozdělit.text Rozdělit.text trochu jinak
Rozdělit.text trochu jinak Nová funkce Valuetotext
Nová funkce Valuetotext





Zjistila jsem, že se v Excelu objevily nové textové funkce. Myslím, že jsou užitečné, proto bych ráda o nich něco napsala.
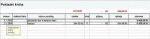
První z nich je Textpřed, která umí vybrat text před zadaným oddělovačem. Tato funkce má tvar
=TEXTPŘED(text;delimiter; instance_num; match_mode; match_end; if_not_found),
kde argument text je text, ve kterém se má hledat, delimiter je prakticky oddělovač, bod, před kterým se text vybere. Argument instance_num je pořadové číslo oddělovače, před kterém se má text vybrat (výchozí nastavení je 1). Záporné číslo začne vyhledávat v textu od konce. Další argument match_mode určuje, zda se při hledání textu rozlišují velká a malá písmena (0 - rozlišují se malá písmena, pokud se zadá 1, pak se malá a velká písmena nerozlišují. Argument match_end zachází s koncem textu jako s oddělovačem, ve výchozím nastavení je text přesnou shodou. A poslední argument if_not_found je text, který se má zobrazit, pokud nebyla nalezena žádná shoda. Ve výchozím nastavení se vrátí #Není k dispozici (#N/A).
Další zajímavou funkcí je Textza, pracuje na stejném principu jako předchozí funkce jen s tím rozdílem, že se nevrací část před oddělovačem, ale za oddělovačem. Význam argumentů je prakticky stejný. Její tvar je
=TEXTZA(text;delimiter; instance_num; match_mode; match_end; if_not_found),
kde argument text je text, ve kterém se má hledat, delimiter je prakticky oddělovač, bod, za kterým se text vybere. Argument instance_num je pořadové číslo oddělovače, po kterém se má text vybrat (výchozí nastavení je 1). Záporné číslo začne vyhledávat v textu od konce. Další argument match_mode určuje, zda se při hledání textu rozlišují velká a malá písmena (0 - rozlišují se malá písmena, pokud se zadá 1, pak se malá a velká písmena nerozlišují. Argument match_end zachází s koncem textu jako s oddělovačem, ve výchozím nastavení je text přesnou shodou. A poslední argument if_not_found je text, který se má zobrazit, pokud nebyla nalezena žádná shoda. Ve výchozím nastavení se vrátí #NENÍ_K_DISPOZICI (#N/A).
Další zajímavou funkcí je Rozdělit.text, která umí text rozdělit podle zadaného oddělovače (lze ji přirovnat k nástroji Text do sloupců). Její tvar je
=ROZDĚLIT.TEXT(text; col_delimiter; row_delimiter; ignore_empty; match_mode; pad_with),
kde text je text, který se má rozdělit. Argument col_delimiter je oddělovač pro dělení mezi sloupci, row_delimiter je pak oddělovač pro řádky. Dále ignore_empty může vytvořit prázdnou buňku u dvou po sobě jdoucích oddělovačů (nepravda), výchozím argumentem je pravda. Argument match_mode určuje, zda se při hledání textu rozlišují velká a malá písmena a poslední argument pad_with je obsah, který se má zobrazit, když pro danou buňku by hodnota nebyla. Pokud se argument neuvede, zobrazí se #NENÍ_K_DISPOZICI (#N/A).
Jinak pokud oddělovač nebude nalezen, tak funkce vrátí celý nerozdělení zadaný text. Možné je i zadání více oddělovačů – jen je potřeba je zapsat středníkem oddělené ve složených závorkách, poradí si také i s textem s více výskyty oddělovače – výsledkem pak bude jednoduše více buněk.
Poslední z přidaných textových funkcí je Valuetotext (neplést s funkcemi Hodnota.na.text nebo Zaokrouhlit.na.text) umožňuje převod netextových (např. číselných) dat do formátu textu. Je třeba si ale uvědomit, že přesný výsledek závisí na obsahu původních buněk. Prostě textové hodnoty zůstanou textovými, čísla se převedou do podoby čísel uložených jako text, horší je to s datumy a časy. Její tvar je
=VALUETOTEXT(hodnota; formát),
kde argument hodnota je ten obsah, který má být vrácen jako text. Další argument format je nepovinný, a bude říkat informace o formátu vrácených dat. Výchozí nastavení (0) je, že funkce vrátí tvar textu shodný s obecným formátem. Pokud se zadá 1, pak se jedná o striktní formát, kde třeba text bude ohraničen uvozovkami.
Osobně mi ale připadá asi lepší funkce Hodnota.na.text, ve které se dá navolit libovolný formát podle potřeby.