

Tabelátor, tabulátor, zarážka – k čemu to slouží
 Přehled tabulátorů
Přehled tabulátorů Tabulátory na pravítku
Tabulátory na pravítku Okno pro nastavení
Okno pro nastavení Tabulátory s vodící linkou
Tabulátory s vodící linkou




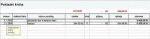
Prostě více názvů pro jednu věc. Když je třeba napsat text do sloupců, které mají být srovnané, například inventář, seznam knih, výrobků, … použijte tabulátory. Při zarovnání textu mezerami by při posunu, formátování nebo přechodu na jinou tiskárnu se vaše urovnání rozhodí a prakticky by se mohlo začít s úpravou znovu. Je lepší použít vlastní tabulátory, které se nastavují přesně na centimetry.
Word má čtyři základní typy tabulátorů (používá se také výraz zarážka) pro zarovnání: levý, na střed, pravý, desetinný a pátý typ tabulátoru pro vytvoření svislé čáry v zadané poloze: sloupcový. Podle potřeby zarovnání se vybere vždy ten, který právě bude vyhovovat. Tabulátory lze nastavit dvojím způsobem.
Rychlejší způsob je pomocí pravítka a myši. Jak? Je třeba umístit kurzor do odstavce, kam se má psát text za pomocí tabulátorů. Potom se již tedy stačí podívat do levého horním rohu u pravítka značky levé zarážky. Když se na ni klepne, změní se na značku zarážky na střed, dalším klepnutím na značku pravé zarážky, potom desetinné, sloupcové, a nakonec se zde ještě zobrazí značky pro odsazení odstavců (těch si prakticky všímat nemusí). Důležité je to, že po opakovaném klepnutí se nakonec znovu objeví značka levé zarážky, pak na střed, ….
To znamená, že klepnutím se vybere potřebný tabulátor a pak se klepne myší na určité místo na pravítku. Vybraný tabulátor se zde okamžitě objeví a už se může začít využívat nebo nastavit podle potřeby ještě tabulátory další. Při vlastním psaní se pak používá klávesu tabulátoru (Tab), která posouvá kurzor přesně na následující polohu nastaveného tabulátoru. Na konci řádku se pak vždy stiskne klávesa Enter nebo případně Shift+Enter (tvrdé zalomení řádku – pozor neukončuje odstavec, to znamená, že na konci části s tabulátory se pak musí použít klávesa Enter). Na další řádek se nemá přecházet stiskem klávesy Tab.
Tímto způsobem pak se již napíše text bez zvláštního posouvání, zbytečných mezer nebo složitého zarovnávání.
Pokud je třeba tabulátor odstranit, uchopí se myší a odhodí dolů kolmo z pravítka. Jestliže se má pouze přemístit, uchopí se myší a přesune se do nové polohy. Je třeba si dát pozor na to, aby text, pro který se poloha tabulátoru mění, byl vybrán do bloku.
Druhý způsob nastavení tabulátorů je pomocí dialogového okna Tabulátory. V této verzi Wordu se už neotevře přímo, ale pomocí dialogového okna Odstavec, kde se dole nachází tlačítko Tabulátory. Případně se dá libovolně na pravítku umístit jeden tabulátor a pak na něj udělat dvojklik. Tím se otevře dialogové okno, ve kterém se nastaví jednotlivé polohy vybraných tabulátorů číselně. Navíc si zde může nastavit i velikost tabulátoru standardního.
Když se běžně používají tabulátory, vznikne obvykle odskok do dané pozice tabulátoru (zarážky) bez znaků. Jestliže se však zvolí tabulátor s vodicím znakem, po stisku klávesy Tab se vypíše až do dané polohy například řádek teček, čárek nebo plná souvislá čára. To lze využít při přípravě různých formulářů, dotazníků či tvorbě obsahu.